Twitter System Design Part-1
Twitter is an American microblogging and social networking service on which users post and interact with messages known as “tweets”. Registered users can post, like, and retweet tweets, but unregistered users can only read those that are publicly available.
Functional Requirements:
- Tweets Obviously
- User Timeline
- Home Timeline
- Trending Tweets (HashTags(#), Topics)
- Search Tweet
Non Functional Requirements:
- Highly Available
- Eventual Consistency (It’s ok if a tweet is shown to followers after some time).
- Low Latency (Real Time)
Estimations:
Characters Supported per tweet: 280 Characters
Write Requests: 1000 tweets/sec
Read Requests: 1000,000 tweets/sec
So It’s a read-heavy system.
Storage Estimations:
Tweets/Sec: 1000*280 = 280000 Bytes/sec = 280 KB/sec ~ 0.3 MB/sec
Tweets/Day: 0.3*3600*24 = 26 GB/Day
Jamboard Link:
Database:

Let’s see how we use cache to store tweets in order to reduce latency.
For this example, I am taking Redis as my cache.
We can use a stored set to store tweets and followers.
Example:
- <user_id1>_tweets: {1,2,3..}
- <user_id2>_tweets: {4,5,6..}
- <user_id1>_follows: {1,2,3…}
- <user_id2>_follows: {4,5,6…}
For fast loading, we can store 5 years of data in Redis:
Total Space: (26 GB/Day) * (365*5 Day) = 65700 GB ~ 66 TB
User Timeline:
For the user timeline, we need to store all the tweets the user tweeted.
Let’s discuss how we store and read tweets from Redis/DB.
We can use a sorted set as discussed above to store tweets based on some scores say timestamp. Say we can fetch the top 20 tweets and once we read the top 10 tweets we can call from the backend to load 10 more we can use the timestamp of the last tweet (i.e the 20th tweet in a window) as the offset here.
Here’s the example:

Let’s see how we can store tweets in Redis. For this, we can use set commands.
Example:
tweet_id_1: “Hello There!”
tweet_id_2: “Check out my new article”
We can reduce key characters from tweet_id to T_ID to save some space.
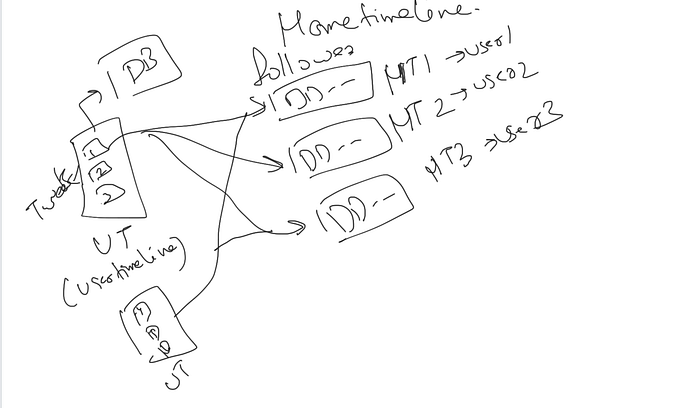
HomeTime:
For the home timeline let’s discuss the steps:
- Get followers
- Get latest tweets
- Merge and Display Tweets
For each user, we can maintain a home timeline basically key-value just like we use to store tweets in the user timeline.
Example:
H_U_ID1: {1,2,3…}
H_U_ID2: {3,4,5…}
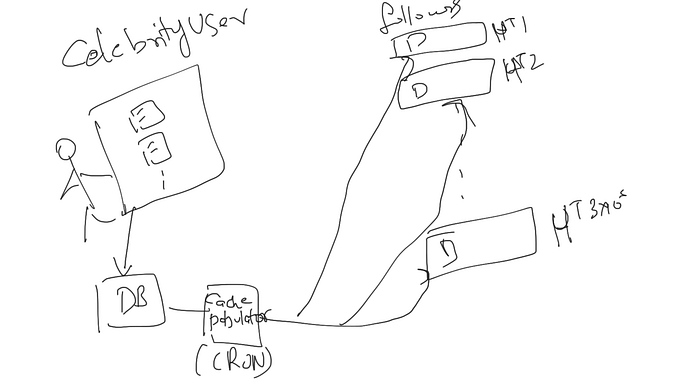
So we can use a cache populator service to populate home timeline data in Redis. For online users, we can populate the tweet from a user to its followers directly. But we can’t do the same thing with celebrity tweets right as they have millions of followers.
Now for Celebrity tweets what we can do is wait and let the cache populator service(CRON) update tweets in individual user hometime caches.
So In short:
- For Normal Users: Tweets push to followers' home timelines.
- For Celebrity Users: Tweets pull to followers’ home timelines.
Example:
Services:
- User App/ Web App: Used to write and read tweets.
- Tweet Write Service: Handle all the write request
- Tweet Write Consumer Service: To save data in the database and Redis cache based on the user and home timeline.
- Tweet Read Service: Handle all the read requests.
- API Gateway: That forwards traffic to different Load balancers (Path-Based API Gateway).
- Cache Populator Service: Explained Above
- Notification Service. (Real-Time)
- Search Service: (Will be discussed In Part 2)
- Trend Service: (Missing Here Will be discussed In Part 2)
High-Level Architecture:
ThankYou. Please do give suggestions.
